Course link This course is a brief introduction to LangChain and base of a RAG pipeline. A very basic approach. That covers only a small part of LangChain environment.
 Resource: Course Documents
Resource: Course Documents
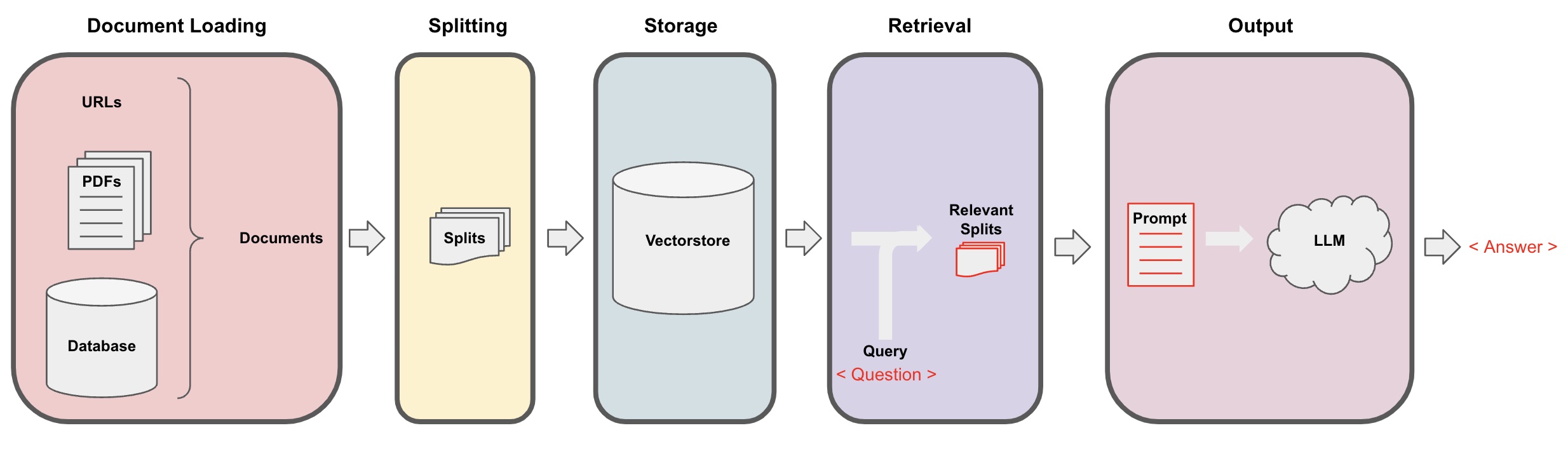
Document Loading
LangChain has More than 80 documents loaders. In this course 3 of them are mentioned.
- PDFs: Of course the most used is PyPDFLoader, the thing here is I prefer PyMuPDF. Especially for its support on tesseract
- YouTube: This approach is downloads the video, then extracts the audio and finally extracting transcript with OpenAI’s whisper
- Notion: Notion extracts spaces in
Markdown/CSVformat. This loader reads these files and constructs aDocumentfrom them
Document Splitting (aka. Chunking)
This is one of the most important part of the whole RAG system. In this course 3 different splitter taught.
1. CharacterTextSplitter
- This method splits by using only one separator. Default is
"\n\n" - Chunk size measurement is number of characters
2.
RecursiveCharacterTextSplitter - This method takes a list of separators and splits the text respectively to the list.
For example if the list is
["\n\n", "\n", "\n\t\, ".", ""]the text first split by"\n\n"and then by"\n"and"\n\t"and so. Additionally, these separators can be a regex. - Chunk size measurement number of chars
3.
SemanticChunkerAs of 24.05.2024 this method is still in
langchain_experimentallibrary. This method uses an embedding model first to read the whole text then creates chunks that are semantically similar within a chunk. Therefore it doesn’t use an explicit separator. Instead it uses breakpoints which are:
Percentile: In this method, all differences between sentences are calculated, and then any difference greater than the X percentile is split. Default: 0.95
Standard Deviation In this method, any difference greater than X standard deviations is split. Default: 3
Interquartile In this method, the interquartile distance is used to split chunks. Default: 1.5
Vector Stores & Embedding
LangChain provides both open source and paid services. Detailed docs are for vector stores and for embeddings
Retrieval
This tutorial only covers chroma as vector database and uses similarity_search as base query method.
To overcome duplicated reposes suggests max_marginal_relevance_score
Additional to these methods, also there are some more advanced retrievers. For example, if user asks for a specific document that needs to be filtered through metadata (eg. “What did say about regression in third lecture?”), SelfQueryRetriever can generate a filter for metadata from the given query.
Strict Prompt Descriptions are really important as they are passed to the LLM and expected response will include parts from these descriptions. It’s really important them to be clear and detailed.
Compression
The actual information might be within the irrelevant text, and the straightforward similarity might not be enough to catch this information. Compression aims to solve this
Later on the course the three techniques MMR, SelfQueryRetriver and ContexualCompressionRetriever are combined together.
Other Types of Retrieval
There is also other types of retrieval like SVM or TF-IDF. These methods are not told much and I don’t think they will be used much either.
Question Answering
Covers creation of a prompt template and a simple usage from langchain.chains library.
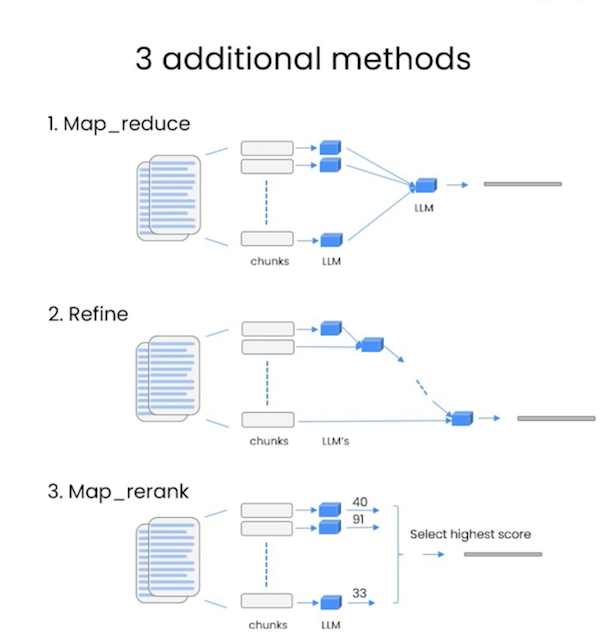
The issue they focus here is another approach for handling of retrieved chunks. Instead of using them all together at once. But what if all the chunks, prompts, query are exceeds the context length of the LLM? The course suggests three chain types. One another thing that these methods also add another call to LLM.
Concerns First, these methods adds additional calls to LLM, resulting more tokens and latency. Second, if the chunks included in these techniques contain irrelevant information, they may end up in confusing the LLM. Therefore, having even worse results.
 Resource: Course documents
Resource: Course documents
Map Reduce
In this technique all the chunks sent to LLM to get an answer. And then all of these answers are combined with an LLM into one answer.
Refine
With this technique each chunk sent to LLM respectively including the former answer until the final chunk reached. The final answer will contain all the contexts from all of the chunks used.
Map Rerank
Again all the retrieved chunks sent to LLM with the query and then asked to answer with a score of how well the answer is for the given query and chunk. Then from these scores the highest one is selected to be the final answer.
Memory
Adds memory to the chat that created in Question Answering so followup question can be asked.
Comments